AI portrait suite
Interval makes it easy to leverage Python's rich ecosystem of machine learning and AI libraries. In this example, we'll use Interval to build a full-fledged generative image app, with functionality to train a custom model on images you upload, generate new images, and display them in a gallery.
How it works
Stable Diffusion is a powerful AI model that can generate images from text descriptions. We'll build our portrait app with this model, along with a handful of other open-source libraries and notebooks like Huggingface diffusers and Joe Penna's Dreambooth repo.
To try it out on a GPU or follow along in code, here's our repo with the completed app.
info
- To generate images in a reasonable amount of time, and to fine-tune Stable Diffision on your own pictures, you'll need to run the Interval actions we create in this tutorial on a GPU. We used RunPod.
- This tutorial is optimized for training on images of people for generating portraits.
- It's generally good practice to utilize virtual environments for running python code and managing packages, but this tutorial assumes you're handling environments yourself. (Most cloud GPUs providers setup a python environment for you by default.)
First some preliminary setup. We'll create some directories for organizing our training images and AI generated outputs, download a notebook for training a model, and we'll install its required dependencies.
mkdir training_images
mkdir trained_models
mkdir outputs
git clone https://github.com/huggingface/diffusers
git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion
cd Dreambooth-Stable-Diffusion
pip install omegaconf
pip install einops
pip install pytorch-lightning==1.6.5
pip install test-tube
pip install transformers
pip install kornia
pip install setuptools==59.5.0
pip install pillow==9.0.1
pip install torchmetrics==0.6.0
pip install -e .
pip install protobuf==3.20.1
pip install gdown
pip install -qq diffusers transformers ftfy
pip install huggingface_hub
pip install captionizer==1.0.1
pip install safetensors
git clone https://github.com/djbielejeski/Stable-Diffusion-Regularization-Images-person_ddim.git regularization_images
cd ..
pip install interval-sdk
pip install -e git+https://github.com/CompVis/taming-transformers.git@master#egg=taming-transformers
pip install -e git+https://github.com/openai/CLIP.git@main#egg=clip
We'll start building our app by creating an action that trains a new, custom Stable Diffusion model on images you provide. Let's flesh out a basic Interval action to build on.
import os
from interval_sdk import Interval, IO
interval = Interval(
os.environ.get("INTERVAL_KEY"),
)
@interval.action
async def train_model(io: IO):
model_name = await io.input.text(
"What do you want to call your custom model?",
help_text='This will also be used as the "trigger word" for your trained model.',
).validate(
lambda name: "Model name must be one word (no spaces)"
if name.strip().count(" ") > 0
else None
)
return f"TODO: Train {model_name} model"
interval.listen()
This creates a UI to collect the name of the model, which we'll also use as the "trigger word" that the model will learn to associate with the images you provide. For simplicity, we've added a validation to ensure only a single word is provided.
tip
To give the model a nice head start in figuring out what you look like, you can use https://starbyface.com/ to find the celebrity that looks most similiar to your images, and utilize their name as the "trigger word".
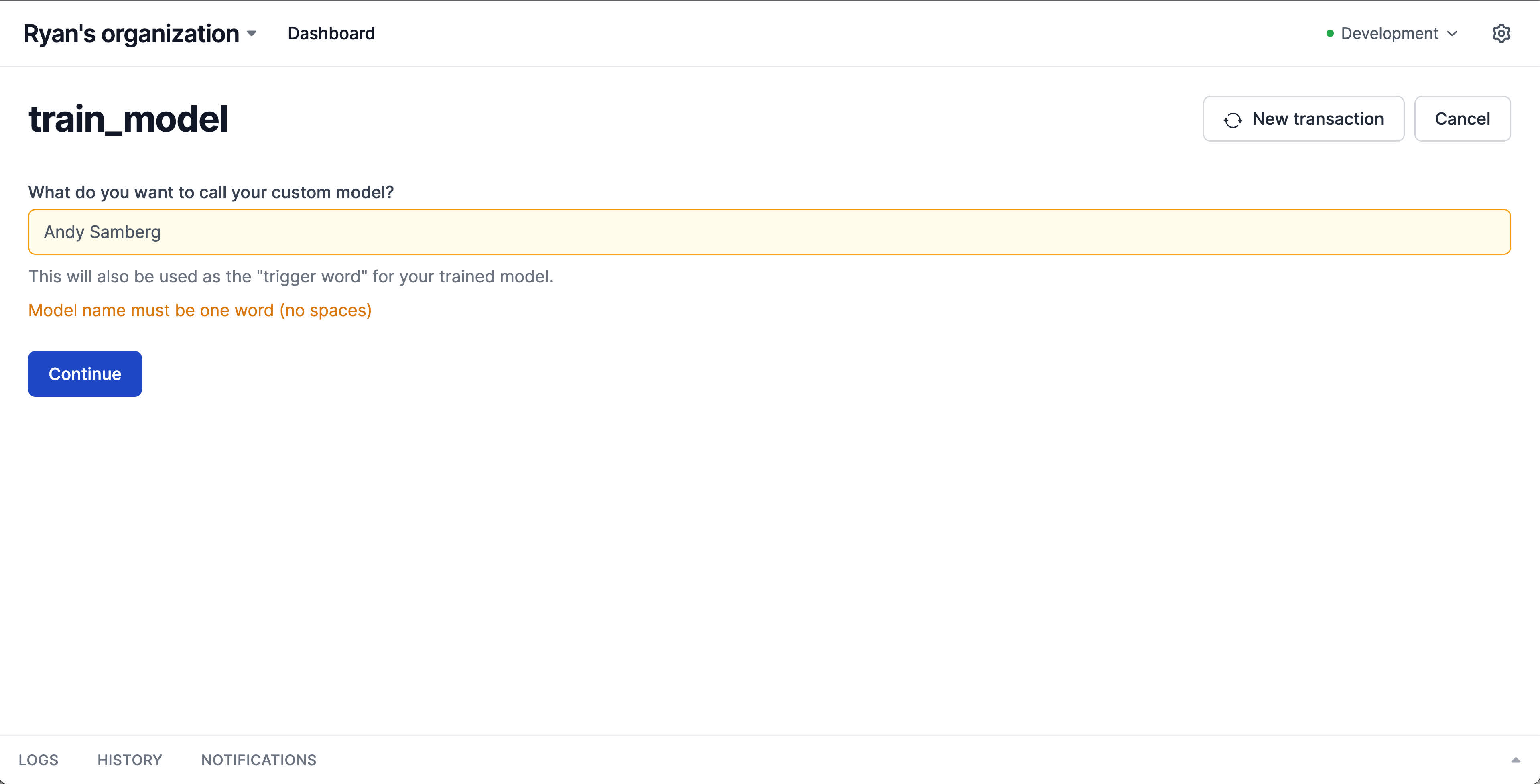
Next we need some images to train your custom model on. With a single I/O method we add a step to our train_model action that allows easily uploading any number of images:
import os
from interval_sdk import Interval, IO
interval = Interval(
os.environ.get("INTERVAL_KEY"),
)
training_images_dir = "./training_images"
@interval.action
async def train_model(io: IO):
model_name = await io.input.text(
"What do you want to call your custom model?",
help_text='This will also be used as the "trigger word" for your trained model.',
).validate(
lambda name: "Model name must be one word (no spaces)"
if name.strip().count(" ") > 0
else None
)
images = await io.input.file(
"Upload images to train your model on",
help_text="10-20 images is best, ideally with a variety of poses, lighting, distance, but also generally as close as possible to the kind of images you're trying to generate.",
).multiple().validate(lambda files: "You must provide an even number of files" if len(files) % 2 != 0 else None)
for image in images:
filename = f"{training_images_dir}/{model_name}/{image.name}"
os.makedirs(os.path.dirname(filename), exist_ok=True)
with open(filename, "wb") as f:
f.write(image.read())
return f"TODO: Train {model_name} model"
interval.listen()
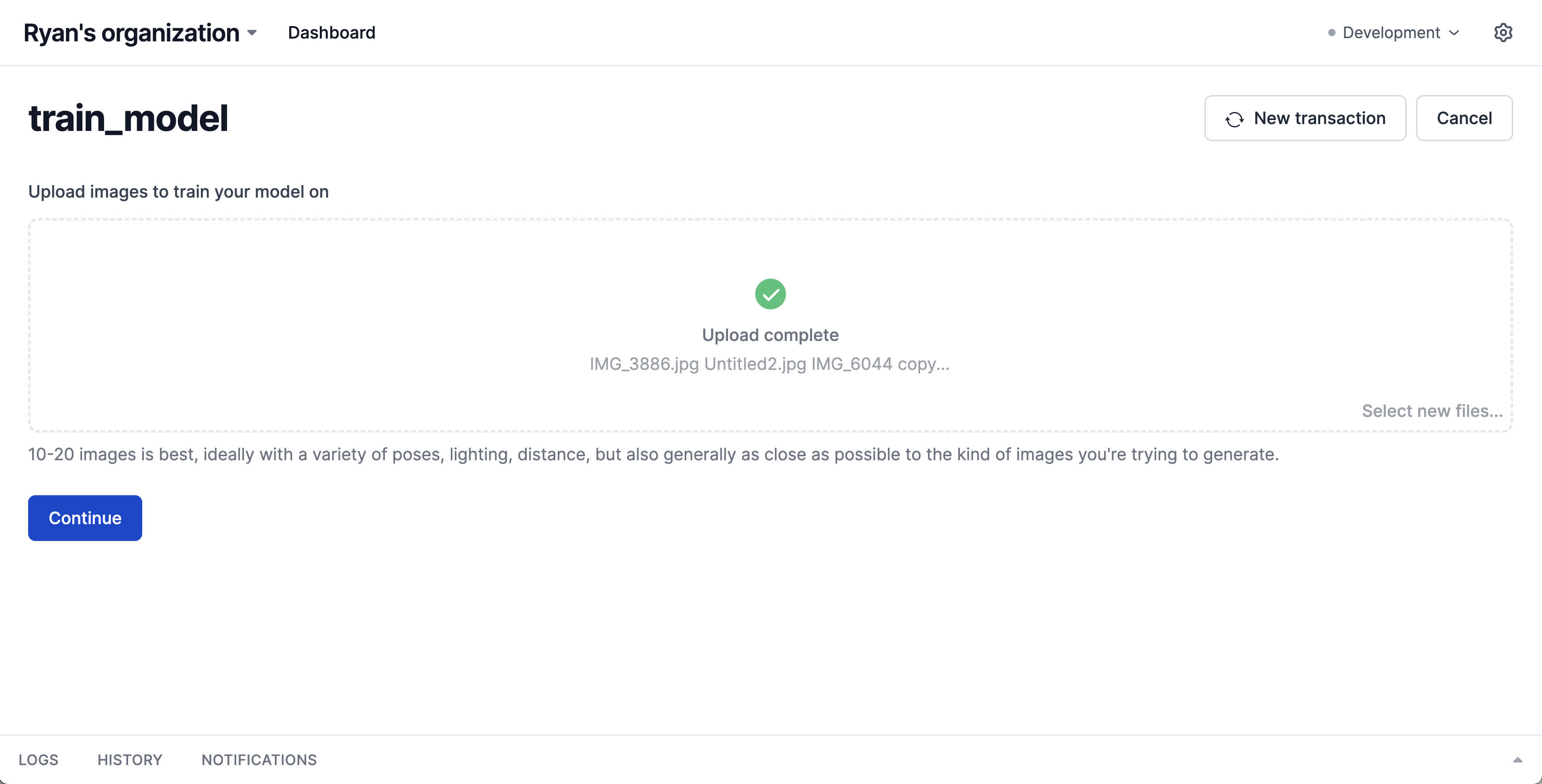
Once the files have been uploaded, we save them locally for training.
But we still need a model to train! This process doesn't train a model from scratch—instead we'll download the weights of Stable Diffusion from Huggingface and fine-tune from there. We'll add a step in our action to download the model, move it to where our training notebook expects it to be, and display a loading spinner in the meantime.
import os
import subprocess
from interval_sdk import Interval, IO, ctx_var
from huggingface_hub import hf_hub_download
training_images_dir = "./training_images"
base_model_path="./Dreambooth-Stable-Diffusion/model.ckpt"
interval = Interval(
os.environ.get("INTERVAL_KEY"),
)
@interval.action
async def train_model(io: IO):
ctx = ctx_var.get()
model_name = await io.input.text(
"What do you want to call your custom model?",
help_text='This will also be used as the "trigger word" for your trained model.',
).validate(
lambda name: "Model name must be one word (no spaces)"
if name.strip().count(" ") > 0
else None
)
images = await io.input.file(
"Upload images to train your model on",
help_text="10-20 images is best, ideally with a variety of poses, lighting, distance, but also generally as close as possible to the kind of images you're trying to generate.",
).multiple().validate(lambda files: "You must provide an even number of files" if len(files) % 2 != 0 else None)
for image in images:
filename = f"{training_images_dir}/{model_name}/{image.name}"
os.makedirs(os.path.dirname(filename), exist_ok=True)
with open(filename, "wb") as f:
f.write(image.read())
if not os.path.isfile(base_model_path):
await ctx.loading.start("Downloading model to train...")
model_path = hf_hub_download(
repo_id="runwayml/stable-diffusion-v1-5",
filename="v1-5-pruned.ckpt",
)
proc = subprocess.Popen(["readlink", "-f", model_path], stdout=subprocess.PIPE)
real_path = proc.stdout.read()
subprocess.run(
[
"mv",
real_path.strip(),
base_model_path,
]
)
return f"TODO: Train {model_name} model"
interval.listen()
OK! Now we can train the model. We'll add a confirmation step before running it, since it takes around an hour (on an RTX A5000). Once the notebook finishes running, we'll convert the model to a format that works with the diffusers library for a friendlier API to generate images with.
import os
import subprocess
import glob
from interval_sdk import Interval, IO, ctx_var
from huggingface_hub import hf_hub_download
from diffusers.pipelines.stable_diffusion.convert_from_ckpt import load_pipeline_from_original_stable_diffusion_ckpt
training_images_dir = "./training_images"
base_model_path="./Dreambooth-Stable-Diffusion/model.ckpt"
trained_models_dir = "./trained_models"
interval = Interval(
os.environ.get("INTERVAL_KEY"),
)
@interval.action
async def train_model(io: IO):
ctx = ctx_var.get()
model_name = await io.input.text(
"What do you want to call your custom model?",
help_text='This will also be used as the "trigger word" for your trained model.',
).validate(
lambda name: "Model name must be one word (no spaces)"
if name.strip().count(" ") > 0
else None
)
images = await io.input.file(
"Upload images to train your model on",
help_text="10-20 images is best, ideally with a variety of poses, lighting, distance, but also generally as close as possible to the kind of images you're trying to generate.",
).multiple().validate(lambda files: "You must provide an even number of files" if len(files) % 2 != 0 else None)
for image in images:
filename = f"training_images/{model_name}/{image.name}"
os.makedirs(os.path.dirname(filename), exist_ok=True)
with open(filename, "wb") as f:
f.write(image.read())
if not os.path.isfile(base_model_path):
await ctx.loading.start("Downloading model to train...")
model_path = hf_hub_download(
repo_id="runwayml/stable-diffusion-v1-5",
filename="v1-5-pruned.ckpt",
)
proc = subprocess.Popen(["readlink", "-f", model_path], stdout=subprocess.PIPE)
real_path = proc.stdout.read()
subprocess.run(
[
"mv",
real_path.strip(),
base_model_path,
]
)
confirmed = await io.confirm("Ready to train?", help_text="This could take a while...")
if confirmed:
await ctx.loading.start(title="Training model on your images...")
subprocess.run(
[
"python",
"Dreambooth-Stable-Diffusion/main.py",
"--base",
"Dreambooth-Stable-Diffusion/configs/stable-diffusion/v1-finetune_unfrozen.yaml",
"-t",
"--actual_resume",
base_model_path,
"--reg_data_root",
"Dreambooth-Stable-Diffusion/regularization_images/person_ddim",
"-n",
model_name,
"--gpus",
"0,",
"--data_root",
f"{training_images_dir}/{model_name}",
"--max_training_steps",
"2000",
"--class_word",
"person",
"--token",
model_name,
"--no-test",
]
)
await ctx.loading.start(title="Done training! Converting to diffusers format...")
latest_model_dir = max(glob.glob(f"./logs/{model_name}*"), key=os.path.getmtime)
pipe = load_pipeline_from_original_stable_diffusion_ckpt(
checkpoint_path=f"{latest_model_dir}/checkpoints/last.ckpt",
)
pipe.save_pretrained(f"{trained_models_dir}/{model_name}", safe_serialization=None)
return "All done!"
interval.listen()
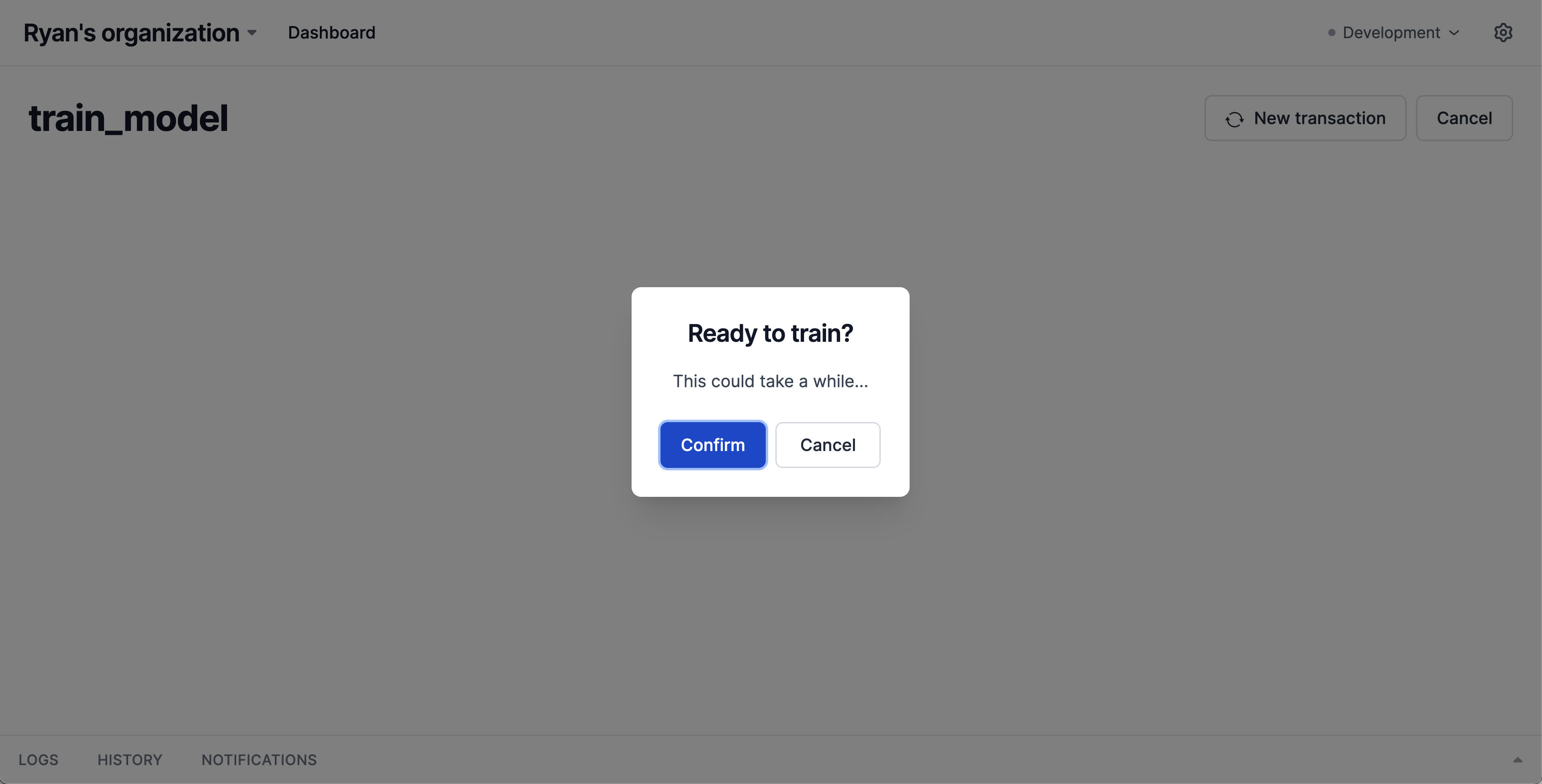
Now (once the lengthy training run is complete) we can generate some images! Let's create a new action to do so.
import os
import glob
import base64
import subprocess
import io as _io
from datetime import datetime
from interval_sdk import Interval, IO, ctx_var
from huggingface_hub import hf_hub_download
from diffusers.pipelines.stable_diffusion.convert_from_ckpt import load_pipeline_from_original_stable_diffusion_ckpt
from diffusers import StableDiffusionPipeline
import torch
training_images_dir = "./training_images"
base_model_path="./Dreambooth-Stable-Diffusion/model.ckpt"
trained_models_dir = "./trained_models"
outputs_dir = "./outputs"
interval = Interval(
os.environ.get("INTERVAL_KEY"),
)
@interval.action
async def generate(io: IO):
models = [ f.name for f in os.scandir(trained_models_dir) if f.is_dir() ]
[prompt, model] = await io.group(
io.input.text(
"What's the prompt?",
help_text='To activate your trained images include "triggerword person" in the prompt.',
),
io.select.single("Which model do you want to use?", options=models),
)
ctx = ctx_var.get()
await ctx.loading.start(
title="Generating image...",
description="This may take a while on a CPU."
if not torch.cuda.is_available()
else "",
)
pipe = StableDiffusionPipeline.from_pretrained(
f"{trained_models_dir}/{model}"
).to("cuda" if torch.cuda.is_available() else "cpu")
image = pipe(
prompt=prompt,
negative_prompt="multiple people, ugly, deformed, malformed limbs, low quality, blurry, naked, out of frame",
num_inference_steps=50,
).images[0]
now = datetime.now()
image.save(
f"{outputs_dir}/{now.strftime('%Y-%m-%d_%H-%M-%S')}.png", format="PNG"
)
img_bytes = _io.BytesIO()
image.save(img_bytes, format="PNG")
await io.display.image(
"Generated image",
bytes=img_bytes.getvalue(),
size="large",
)
return "All done!"
@interval.action
async def train_model(io: IO):
ctx = ctx_var.get()
model_name = await io.input.text(
"What do you want to call your custom model?",
help_text='This will also be used as the "trigger word" for your trained model.',
).validate(
lambda name: "Model name must be one word (no spaces)"
if name.strip().count(" ") > 0
else None
)
images = await io.input.file(
"Upload images to train your model on",
help_text="10-20 images is best, ideally with a variety of poses, lighting, distance, but also generally as close as possible to the kind of images you're trying to generate.",
).multiple().validate(lambda files: "You must provide an even number of files" if len(files) % 2 != 0 else None)
for image in images:
filename = f"training_images/{model_name}/{image.name}"
os.makedirs(os.path.dirname(filename), exist_ok=True)
with open(filename, "wb") as f:
f.write(image.read())
if not os.path.isfile(base_model_path):
await ctx.loading.start("Downloading model to train...")
model_path = hf_hub_download(
repo_id="runwayml/stable-diffusion-v1-5",
filename="v1-5-pruned.ckpt",
)
proc = subprocess.Popen(["readlink", "-f", model_path], stdout=subprocess.PIPE)
real_path = proc.stdout.read()
subprocess.run(
[
"mv",
real_path.strip(),
base_model_path,
]
)
confirmed = await io.confirm("Ready to train?", help_text="This could take a while...")
if confirmed:
await ctx.loading.start(title="Training model on your images...")
subprocess.run(
[
"python",
"Dreambooth-Stable-Diffusion/main.py",
"--base",
"Dreambooth-Stable-Diffusion/configs/stable-diffusion/v1-finetune_unfrozen.yaml",
"-t",
"--actual_resume",
base_model_path,
"--reg_data_root",
"Dreambooth-Stable-Diffusion/regularization_images/person_ddim",
"-n",
model_name,
"--gpus",
"0,",
"--data_root",
f"{training_images_dir}/{model_name}",
"--max_training_steps",
"2000",
"--class_word",
"person",
"--token",
model_name,
"--no-test",
]
)
await ctx.loading.start(title="Done training! Converting to diffusers format...")
latest_model_dir = max(glob.glob(f"./logs/{model_name}*"), key=os.path.getmtime)
pipe = load_pipeline_from_original_stable_diffusion_ckpt(
checkpoint_path=f"{latest_model_dir}/checkpoints/last.ckpt",
)
pipe.save_pretrained(f"{trained_models_dir}/{model_name}", safe_serialization=None)
return "All done!"
interval.listen()
It would also be nice to view images we've previously created. This is a great use case for Pages. We'll create an Interval page called "Images" and use it to display a gallery of images that our model has generated. We'll also save our images in memory for faster page loads, and we'll add our generate image action as a menu item on this page, to quickly enable creating new images right from the gallery.
import os
import glob
import base64
import io as _io
import subprocess
from datetime import datetime
from interval_sdk import Interval, IO, ctx_var
from interval_sdk.classes.page import Page
from interval_sdk.classes.layout import Layout
from huggingface_hub import hf_hub_download
from diffusers.pipelines.stable_diffusion.convert_from_ckpt import load_pipeline_from_original_stable_diffusion_ckpt
from diffusers import StableDiffusionPipeline
import torch
training_images_dir = "./training_images"
base_model_path="./Dreambooth-Stable-Diffusion/model.ckpt"
trained_models_dir = "./trained_models"
outputs_dir = "./outputs"
images = {}
for image_path in glob.glob(f"{outputs_dir}/*.png"):
with open(image_path, "rb") as f:
data = base64.b64encode(f.read()).decode("utf-8")
images[image_path] = {
"path": image_path,
"url": f"data:image/jpeg;base64,{data}",
}
interval = Interval(
os.environ.get("INTERVAL_KEY"),
)
page = Page(name="Images")
@page.handle
async def handler(display: IO.Display):
return Layout(
title="Images",
description="AI generated images that you've previously generated.",
children=[
display.grid(
"Latest images",
data=[image for key, image in images.items()],
render_item=lambda x: {
"image": {
"url": x["url"],
"aspectRatio": 1,
},
},
default_page_size=8,
is_filterable=False,
),
],
)
@page.action(unlisted=True)
async def generate(io: IO):
models = [ f.name for f in os.scandir(trained_models_dir) if f.is_dir() ]
[prompt, model] = await io.group(
io.input.text(
"What's the prompt?",
help_text='To activate your trained images include "triggerword person" in the prompt.',
),
io.select.single("Which model do you want to use?", options=models),
)
ctx = ctx_var.get()
await ctx.loading.start(
title="Generating image...",
description="This may take a while on a CPU."
if not torch.cuda.is_available()
else "",
)
pipe = StableDiffusionPipeline.from_pretrained(
f"{trained_models_dir}/{model}"
).to("cuda" if torch.cuda.is_available() else "cpu")
image = pipe(
prompt=prompt,
negative_prompt="multiple people, ugly, deformed, malformed limbs, low quality, blurry, naked, out of frame",
num_inference_steps=50,
).images[0]
now = datetime.now()
image_path = f"{outputs_dir}/{now.strftime('%Y-%m-%d_%H-%M-%S')}.png"
image.save(
image_path, format="PNG"
)
img_bytes = _io.BytesIO()
image.save(img_bytes, format="PNG")
data = base64.b64encode(img_bytes.getvalue()).decode("utf-8")
images[image_path] = {
"path": image_path,
"url": f"data:image/jpeg;base64,{data}",
}
await io.display.image(
"Generated image",
bytes=img_bytes.getvalue(),
size="large",
)
return "All done!"
interval.routes.add("images", page)
@interval.action
async def train_model(io: IO):
ctx = ctx_var.get()
model_name = await io.input.text(
"What do you want to call your custom model?",
help_text='This will also be used as the "trigger word" for your trained model.',
).validate(
lambda name: "Model name must be one word (no spaces)"
if name.strip().count(" ") > 0
else None
)
images = await io.input.file(
"Upload images to train your model on",
help_text="10-20 images is best, ideally with a variety of poses, lighting, distance, but also generally as close as possible to the kind of images you're trying to generate.",
).multiple().validate(lambda files: "You must provide an even number of files" if len(files) % 2 != 0 else None)
for image in images:
filename = f"training_images/{model_name}/{image.name}"
os.makedirs(os.path.dirname(filename), exist_ok=True)
with open(filename, "wb") as f:
f.write(image.read())
if not os.path.isfile(base_model_path):
await ctx.loading.start("Downloading model to train...")
model_path = hf_hub_download(
repo_id="runwayml/stable-diffusion-v1-5",
filename="v1-5-pruned.ckpt",
)
proc = subprocess.Popen(["readlink", "-f", model_path], stdout=subprocess.PIPE)
real_path = proc.stdout.read()
subprocess.run(
[
"mv",
real_path.strip(),
base_model_path,
]
)
confirmed = await io.confirm("Ready to train?", help_text="This could take a while...")
if confirmed:
await ctx.loading.start(title="Training model on your images...")
subprocess.run(
[
"python",
"Dreambooth-Stable-Diffusion/main.py",
"--base",
"Dreambooth-Stable-Diffusion/configs/stable-diffusion/v1-finetune_unfrozen.yaml",
"-t",
"--actual_resume",
base_model_path,
"--reg_data_root",
"Dreambooth-Stable-Diffusion/regularization_images/person_ddim",
"-n",
model_name,
"--gpus",
"0,",
"--data_root",
f"{training_images_dir}/{model_name}",
"--max_training_steps",
"2000",
"--class_word",
"person",
"--token",
model_name,
"--no-test",
]
)
await ctx.loading.start(title="Done training! Converting to diffusers format...")
latest_model_dir = max(glob.glob(f"./logs/{model_name}*"), key=os.path.getmtime)
pipe = load_pipeline_from_original_stable_diffusion_ckpt(
checkpoint_path=f"{latest_model_dir}/checkpoints/last.ckpt",
)
pipe.save_pretrained(f"{trained_models_dir}/{model_name}", safe_serialization=None)
return "All done!"
interval.listen()
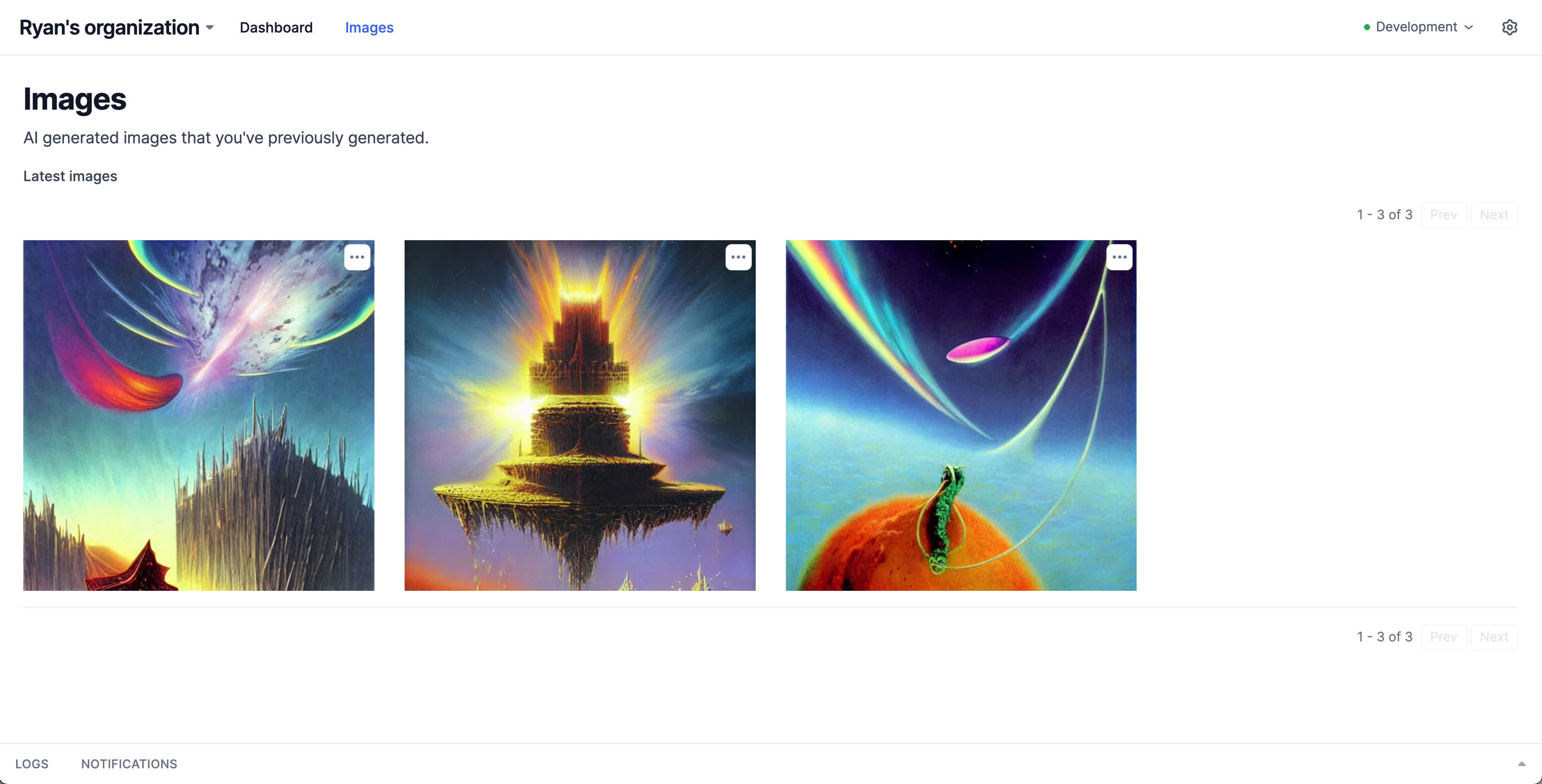
One last thing: While amazing, Stable Diffusion will still occasionally generate some poor quality outputs and/or nightmarish hands. We'll add a new action to delete images and include it in a menu item to easily access it from our image grid.
import os
import glob
import base64
import io as _io
import subprocess
from datetime import datetime
from interval_sdk import Interval, IO, ctx_var
from interval_sdk.classes.page import Page
from interval_sdk.classes.layout import Layout
from huggingface_hub import hf_hub_download
from diffusers.pipelines.stable_diffusion.convert_from_ckpt import load_pipeline_from_original_stable_diffusion_ckpt
from diffusers import StableDiffusionPipeline
import torch
training_images_dir = "./training_images"
base_model_path="./Dreambooth-Stable-Diffusion/model.ckpt"
trained_models_dir = "./trained_models"
outputs_dir = "./outputs"
images = {}
for image_path in glob.glob(f"{outputs_dir}/*.png"):
with open(image_path, "rb") as f:
data = base64.b64encode(f.read()).decode("utf-8")
images[image_path] = {
"path": image_path,
"url": f"data:image/jpeg;base64,{data}",
}
interval = Interval(
os.environ.get("INTERVAL_KEY"),
)
page = Page(name="Images")
@page.handle
async def handler(display: IO.Display):
return Layout(
title="Images",
description="AI generated images that you've previously generated.",
children=[
display.grid(
"Latest images",
data=[image for key, image in images.items()],
render_item=lambda x: {
"menu": [{"label": "Delete", "route": "images/delete", "params": {"path": x["path"]}}],
"image": {
"url": x["url"],
"aspectRatio": 1,
},
},
default_page_size=8,
is_filterable=False,
),
],
)
@page.action(unlisted=True)
async def generate(io: IO):
models = [ f.name for f in os.scandir(trained_models_dir) if f.is_dir() ]
[prompt, model] = await io.group(
io.input.text(
"What's the prompt?",
help_text='To activate your trained images include "triggerword person" in the prompt.',
),
io.select.single("Which model do you want to use?", options=models),
)
ctx = ctx_var.get()
await ctx.loading.start(
title="Generating image...",
description="This may take a while on a CPU."
if not torch.cuda.is_available()
else "",
)
pipe = StableDiffusionPipeline.from_pretrained(
f"{trained_models_dir}/{model}"
).to("cuda" if torch.cuda.is_available() else "cpu")
image = pipe(
prompt=prompt,
negative_prompt="multiple people, ugly, deformed, malformed limbs, low quality, blurry, naked, out of frame",
num_inference_steps=50,
).images[0]
now = datetime.now()
image_path = f"{outputs_dir}/{now.strftime('%Y-%m-%d_%H-%M-%S')}.png"
image.save(
image_path, format="PNG"
)
img_bytes = _io.BytesIO()
image.save(img_bytes, format="PNG")
data = base64.b64encode(img_bytes.getvalue()).decode("utf-8")
images[image_path] = {
"path": image_path,
"url": f"data:image/jpeg;base64,{data}",
}
await io.display.image(
"Generated image",
bytes=img_bytes.getvalue(),
size="large",
)
return "All done!"
@page.action(unlisted=True)
async def delete(io: IO):
ctx = ctx_var.get()
path = ctx.params.get("path", None)
if not path:
return "No image path provided"
if not os.path.isfile(path):
return "No such image to delete"
confirmed = await io.confirm(f"Really delete?", help_text="This can't be undone")
if confirmed:
os.remove(path)
del images[path]
return f"{path} deleted!"
interval.routes.add("images", page)
@interval.action
async def train_model(io: IO):
ctx = ctx_var.get()
model_name = await io.input.text(
"What do you want to call your custom model?",
help_text='This will also be used as the "trigger word" for your trained model.',
).validate(
lambda name: "Model name must be one word (no spaces)"
if name.strip().count(" ") > 0
else None
)
images = await io.input.file(
"Upload images to train your model on",
help_text="10-20 images is best, ideally with a variety of poses, lighting, distance, but also generally as close as possible to the kind of images you're trying to generate.",
).multiple().validate(lambda files: "You must provide an even number of files" if len(files) % 2 != 0 else None)
for image in images:
filename = f"training_images/{model_name}/{image.name}"
os.makedirs(os.path.dirname(filename), exist_ok=True)
with open(filename, "wb") as f:
f.write(image.read())
if not os.path.isfile(base_model_path):
await ctx.loading.start("Downloading model to train...")
model_path = hf_hub_download(
repo_id="runwayml/stable-diffusion-v1-5",
filename="v1-5-pruned.ckpt",
)
proc = subprocess.Popen(["readlink", "-f", model_path], stdout=subprocess.PIPE)
real_path = proc.stdout.read()
subprocess.run(
[
"mv",
real_path.strip(),
base_model_path,
]
)
confirmed = await io.confirm("Ready to train?", help_text="This could take a while...")
if confirmed:
await ctx.loading.start(title="Training model on your images...")
subprocess.run(
[
"python",
"Dreambooth-Stable-Diffusion/main.py",
"--base",
"Dreambooth-Stable-Diffusion/configs/stable-diffusion/v1-finetune_unfrozen.yaml",
"-t",
"--actual_resume",
base_model_path,
"--reg_data_root",
"Dreambooth-Stable-Diffusion/regularization_images/person_ddim",
"-n",
model_name,
"--gpus",
"0,",
"--data_root",
f"{training_images_dir}/{model_name}",
"--max_training_steps",
"2000",
"--class_word",
"person",
"--token",
model_name,
"--no-test",
]
)
await ctx.loading.start(title="Done training! Converting to diffusers format...")
latest_model_dir = max(glob.glob(f"./logs/{model_name}*"), key=os.path.getmtime)
pipe = load_pipeline_from_original_stable_diffusion_ckpt(
checkpoint_path=f"{latest_model_dir}/checkpoints/last.ckpt",
)
pipe.save_pretrained(f"{trained_models_dir}/{model_name}", safe_serialization=None)
return "All done!"
interval.listen()
API methods used
- io.input.text
- io.input.file
- io.confirm
- io.select.single
- io.display.image
- io.display.grid
- ctx.loading.start
- ctx.params